Image Downloader: 图片下载
Image Downloader
1. 简介
- 从图片搜索引擎,爬取关键字搜索的原图URL并下载
- 开发语言python,采用Requests、Selenium等库进行开发
2. 功能
- 支持的搜索引擎: Google, 必应, 百度
- 提供GUI及CMD版本
- GUI版本支持关键词键入,以及通过关键词列表文件(行分隔,使用UTF-8编码)输入进行批处理爬图下载
- 可配置线程数进行并发下载,提高下载速度
- 支持搜索引擎的条件查询(如 :site)
- 支持Google的安全模式开启和关闭
- 支持socks5和http代理的配置,方便科学上网用户
3. 安装
3.1 下载并安装python3.5+
3.2 下载chromedriver并配置[推荐]
- 下载地址
- 选择对应系统、chrome浏览器的版本
- 下载完成后将
chromedriver拷贝到 “本项目文件夹/bin/",或者其他文件夹后添加到PATH中
3.3 下载phantomjs并配置[过时]
- 下载地址
- 选择最新的windows版本下载即可
- 下载完成后将phantomjs.exe拷贝到 “本项目文件夹/bin/",或者其他文件夹后添加到PATH中
3.4 安装相关python库
|
|
4. 如何使用
4.1 图形界面
运行image_downloader_gui.py脚本以启动GUI界面
|
|
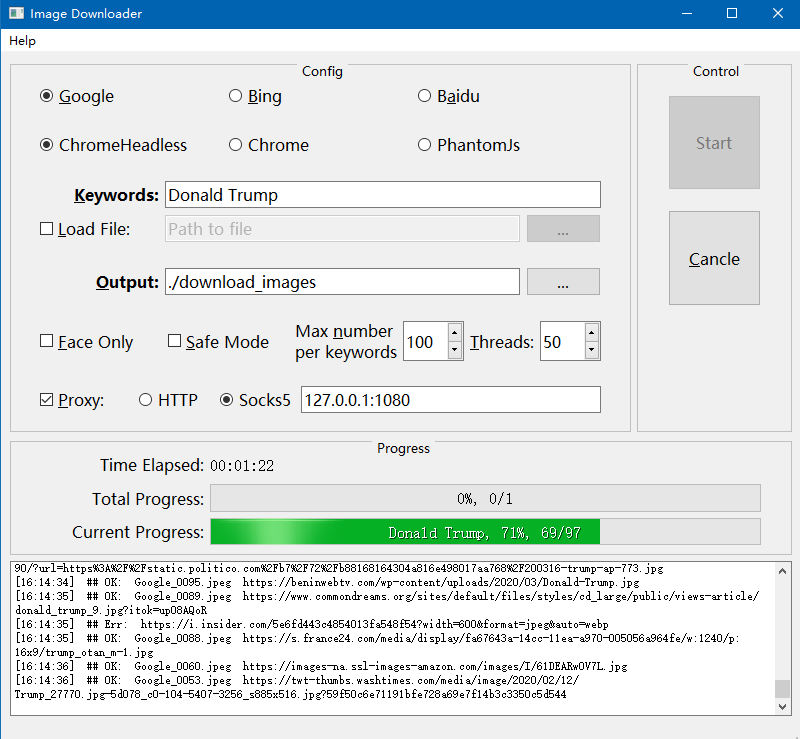
4.2 命令行
|
|
备注
由于Google修改了前端页面,无法直接从单个页面获取全部图片的原始链接,所以需要通过模拟人工点击操作遍历所有图片,因此使用Google引擎来爬取图片时间较长,如需加速可以减少单个关键字的最大图片数量。
许可
- MIT License
- 996ICU License
Reference
1、 https://github.com/sczhengyabin/Image-Downloader
打赏
微信

|
支付宝

|
|---|---|
| 万分感谢 |
- 原文作者:冷眼
- 原文链接:https://cold-eye.github.io/post/python-image-download/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。