一道bat面试题:快速替换10亿条标题中的5万个敏感词,有哪些解决思路?
有十亿个标题,存在一个文件中,一行一个标题。有5万个敏感词,存在另一个文件。写一个程序过滤掉所有标题中的所有敏感词,保存到另一个文件中。
一、AC自动机
一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。
简单地讲,AC自动机就是字典树+kmp算法+失配指针。Python 库 ahocorasick 封装了 AC 自动机,简单易用,而且解决了 UTF-8 字符编码问题。
1
2
3
4
5
6
7
8
9
10
11
12
|
import ahocorasick
patterns = ['中国', '山东省', '威海市', '山东大学', '威海校区'] # 词典
text = '山东大学威海校区坐落于美丽滨城威海市。'
trie = ahocorasick.Automaton()
for index, word in enumerate(patterns):
trie.add_word(word, (index, word))
trie.make_automaton()
for each in trie.iter(text):
print(each)
|
还可以提前创建一个最终的大型自动机,然后对其进行序列化以在以后重新加载。
1
2
3
4
5
|
>>> import cPickle
>>> pickled = cPickle.dumps(trie)
>>> B = cPickle.loads(pickled)
>>> B.get('中国')
(0, '中国')
|
二、flashtext
Flashtext 是一种基于 Trie 字典数据结构和 Aho Corasick 的算法。它的工作方式是,首先它将所有相关的关键字作为输入。使用这些关键字建立一个 trie 字典,如下图所示:
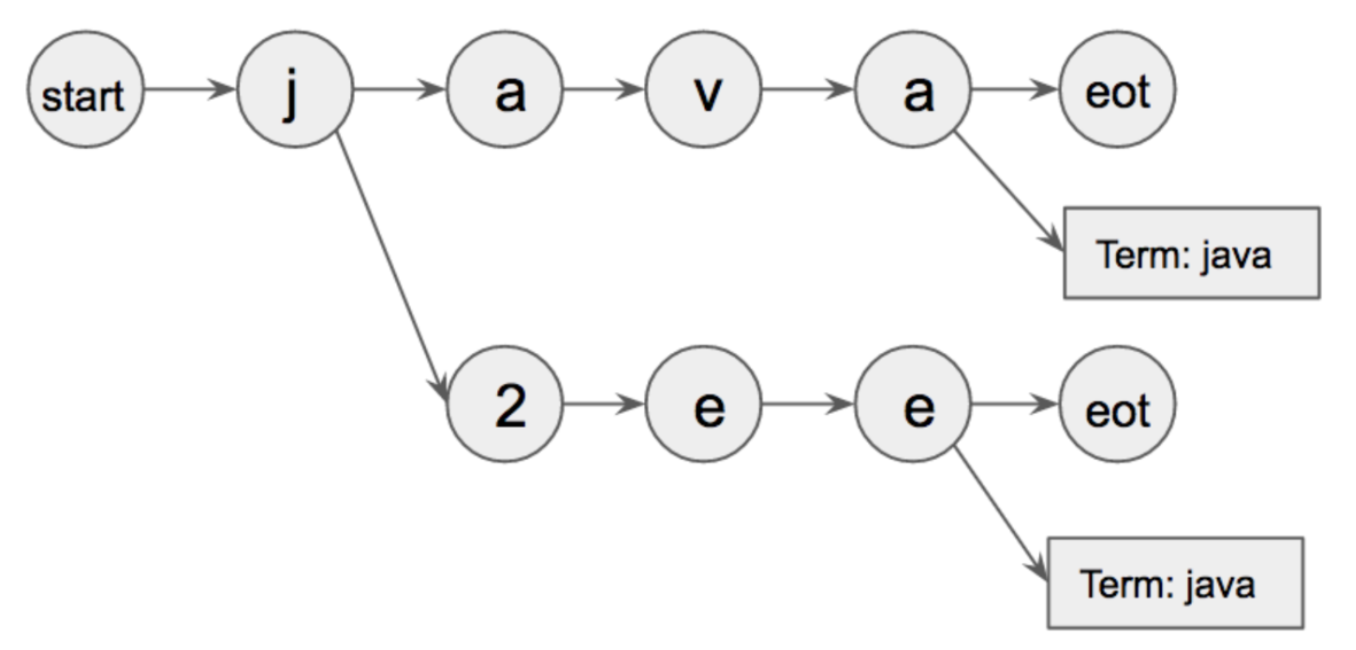 start 和 eot 是两个特殊的字符,用来定义词的边界。
start 和 eot 是两个特殊的字符,用来定义词的边界。
Flashtext 算法那主要分为三部分:
- 构建 Trie 字典 KeywordProcessor
- 新增关键词 add_keyword
- 关键词抽取 extract_keywords
如果要支持中文,需要进行修改。(将文本及字典中的每个汉字之间,以空格分开,这样形式上就和英文相同了)。另外,看到一个flashtext的中文应用,可供参考。
三、DFA算法
DFA即Deterministic Finite Automaton,也就是确定有穷自动机。算法核心是建立了以敏感词为基础的许多敏感词树。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
# -*- coding:utf-8 -*-
import time
time1=time.time()
# DFA算法
class DFAFilter():
def __init__(self):
self.keyword_chains = {}
self.delimit = '\x00'
def add(self, keyword):
keyword = keyword.lower()
chars = keyword.strip()
if not chars:
return
level = self.keyword_chains
for i in range(len(chars)):
if chars[i] in level:
level = level[chars[i]]
else:
if not isinstance(level, dict):
break
for j in range(i, len(chars)):
level[chars[j]] = {}
last_level, last_char = level, chars[j]
level = level[chars[j]]
last_level[last_char] = {self.delimit: 0}
break
if i == len(chars) - 1:
level[self.delimit] = 0
def parse(self, path):
with open(path,encoding='utf-8') as f:
for keyword in f:
self.add(str(keyword).strip())
def filter(self, message, repl="*"):
message = message.lower()
ret = []
start = 0
while start < len(message):
level = self.keyword_chains
step_ins = 0
for char in message[start:]:
if char in level:
step_ins += 1
if self.delimit not in level[char]:
level = level[char]
else:
ret.append(repl * step_ins)
start += step_ins - 1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start += 1
return ''.join(ret)
gfw = DFAFilter()
# 词典路径
words_path = '...'
gfw.parse(words_path)
text="文本"
result = gfw.filter(text)
|
四、总结
以上三种方法都可以实现在大量文本中,进行大规模词典文本快速匹配。应用场景包括:关键词提取,敏感词过滤,知识图谱检索(实体的提取和链接,在一个query中就要求提取出KB中包含的实体的名称)等。
Reference
1、 https://zhuanlan.zhihu.com/p/137584630
2、 https://zhuanlan.zhihu.com/p/158767004
3、 https://blog.csdn.net/u013421629/article/details/83178970
4、 https://mattzheng.blog.csdn.net/article/details/78521871
5、 https://github.com/WojciechMula/pyahocorasick
6、 https://github.com/vi3k6i5/flashtext
7、 https://github.com/cold-eye/flashtext_chinese_nlp_data_augmentation_eda
打赏
微信

|
支付宝

|
| 万分感谢 |
|