数据挖掘3:实操
xmind模块:
- 直接下载xmind工具
- python xmind 库 (便于自动化)
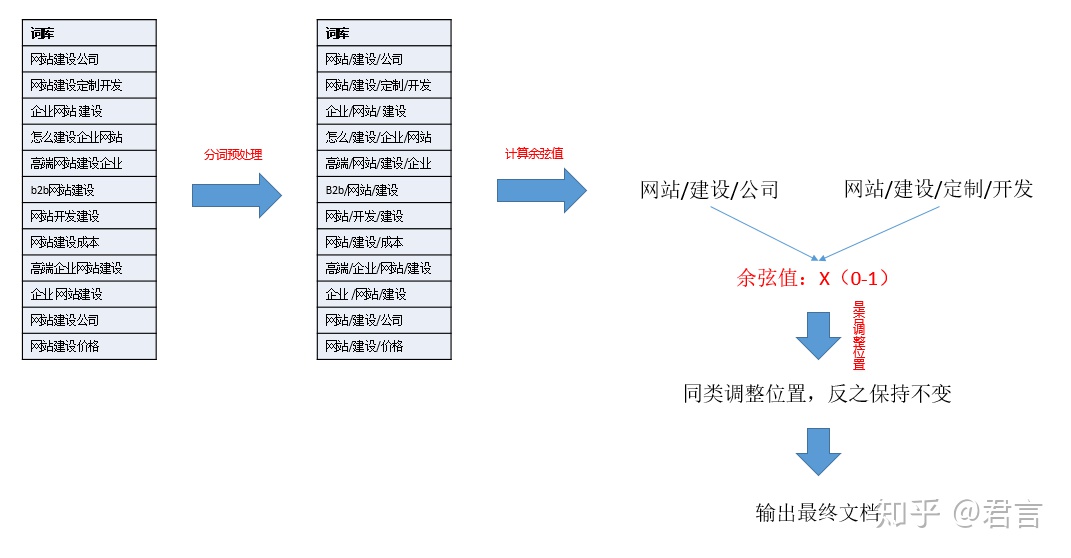
1:词向量文本分类,核心思路是:
-
a: 两两比对词库里的关键词
-
b: 比对时计算两者之间的余弦值
-
c: 根据返回的余弦值选择是否归为一类(修改该关键词所处顺序)
-
d: 输出排序后的结果放在文档里
计算余弦值时每次都要对两个目标词做分词,考虑到重复计算,为节省计算时间,要先对所有词做分词预处理,也就是先把所有词都分词一遍,保存下来,需要使用的时候再拿出来。
2:关键词根提取法,核心思路是:
-
a: 统计top词根N个
-
b: 提取包含词根的对应关键词子集
-
c: 利用xmind模块,在循环中插入对应节点
这套程序思路很简单,甚至没必要画图,但是有几个细节点:
2.1 top词根不一定是合适的 同时 已经被作为节点的词根不应该重复计算
因此需要一个库,记录已经被作为节点的词根
同时,类似”可是“这样的词不具有研究意义,不应该被作为节点,所以需要一个库,事先导入非法词根表
2.2 几百万的关键词,当需要打印的层级较多时,提取各级词频对应词库的交集很耗时,而且分词操作在遍历的过程中可以预计是会重复执行的,因此还是一样要做分词预处理,只不过这个预处理会更复杂一点,需要建立几个词典库:
库1:{id:[长尾词,对应词根集合]}
如:记录id”1“,对应值是一个列表,里面有长尾词”QQ邮箱格式怎么写“,和这个长尾词对应的所有词根集合(set([“QQ”,“邮箱”,“格式”,“怎么”,“写”]))
库2:{长尾词:id}
如:记录”QQ邮箱格式怎么写“,它对应在库1的记录id是”1“
库3:{词根:对应词频}
如:记录”QQ“,它的词频是5,说明它出现在5个关键词里
库4:{词根:对应ID集合}
如:记录”QQ“,它的对应ID集合是set([1,2,3,4,5]),表示有包含它的关键词的对应ID是哪几个
- 倒排索引
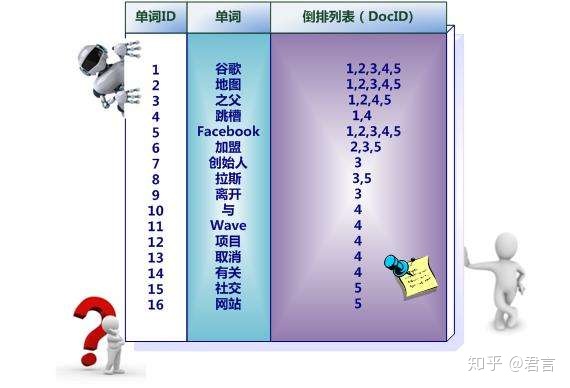
如果对搜索引擎的正排和倒排有了解的话,可以理解这里就是运用了类似的思路,用id对应文档,文档对应词根集合,词根对应文档id集合。
如此一来,无论是提取还是做对比,都可以第一时间返回需要的子集,方便我们计算对比。
我们在百度搜索”QQ邮箱格式怎么写“,你觉得它是怎么工作的呢?
简单粗暴的描述就是分词,然后把包含“QQ”的文章拿出来,包含“邮箱”的文章拿出来,其他同理,然后求文章id的交集,再根据id返回对应的文章,这些文章一定都包含你检索的关键词,当然了,实际上有太多复杂的问题要考虑和处理,简单的理解就是这样。
第三方工具实现关键词根提取法:
工具1:
当我们使用这个工具搜索目标关键词的时候,可以看到下面有一个词频放射图:

其实我就是看到了这个功能后,结合自己的思路,做出来的“关键词根提取法”!
它同样的是由一个核心词,按照词频不断拓展出各层级的词根,通过这个工具一眼就可以看到某个行业的内容结构。
将鼠标放置在某个词根上,左边会显示对于的词频关系介绍。
不同的是他只有节点,没有在节点的最后显示代表性的长尾词,光看词频不太能理解具体的需求是什么。
工具2:
5118-需求图谱-高频需求 搜索目标词后返回来的结果:
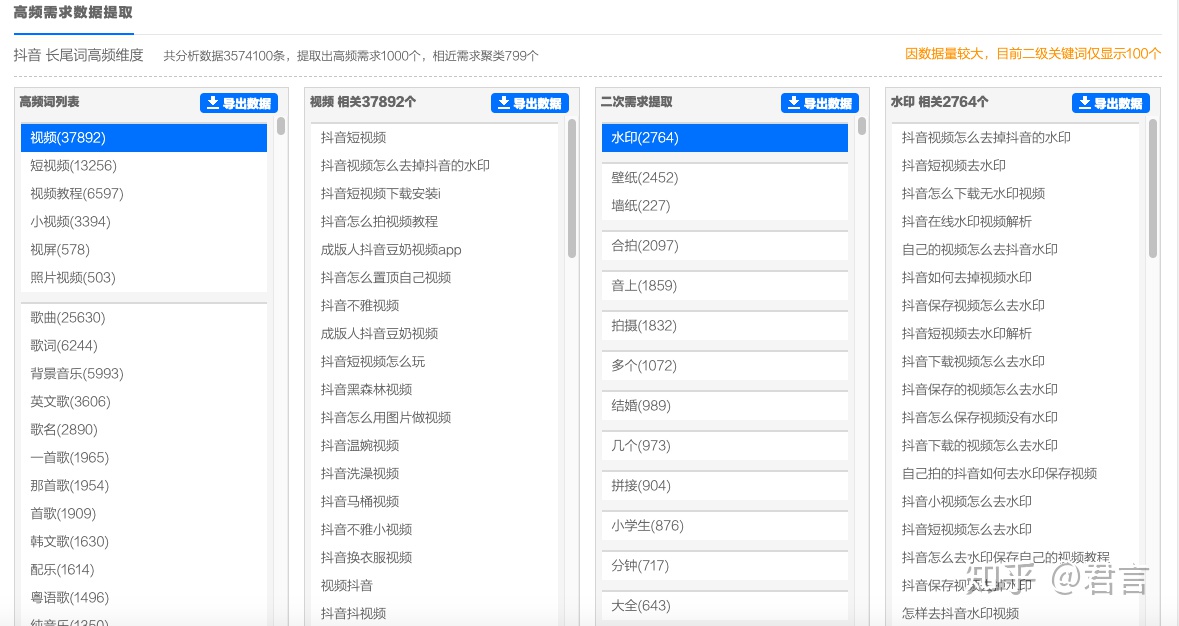
从左到右:
第一列:最高词频的词根
第二列:点击第一列某个词根会显示对应的长尾词
第三列:会从这些长尾词里统计出代表需求的二级词根
第四列:点击每个需求词根又会显示其对应长尾词
因此:
工具1适合我们宏观的了解整个行业脉络
工具2适合我们具体分析微观上的需求
工具很傻瓜化,并没有太多需要讲解的地方。
虽然在直观上思维导图的结构更有利于观察和分类,不过5118给的展示方式也还算可以,至少不影响分析。
当然了,5118毕竟是商业工具,会有数量上的限制。
至于做出“xmind”这样的思维导图,除非一个个去录入,否则没有办法,大量的数据只能是交给程序执行。
Reference
1、 https://zhuanlan.zhihu.com/p/179046666
打赏
微信

|
支付宝

|
|---|---|
| 万分感谢 |
- 原文作者:冷眼
- 原文链接:https://cold-eye.github.io/post/data-mining-3/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。