数据挖掘1:百万级的数据里找项目
项目的重点在于挖掘海量用户的需求,再去做自动化归类,数据量越大,归类越智能,找到的需求就越清晰。
分为两个方向挖掘:广泛和垂直,本篇文章重点讲解“广泛”这一个方向。
接下来我一步步的演示给大家,我是怎么挖掘一个项目的:
两个词挖掘出海量用户需求
这两个神奇的词就是我们经常在使用的:怎么、什么
步骤1:
百度搜索:5118,进入5118官网,使用”查询长尾词“工具,搜索:怎么
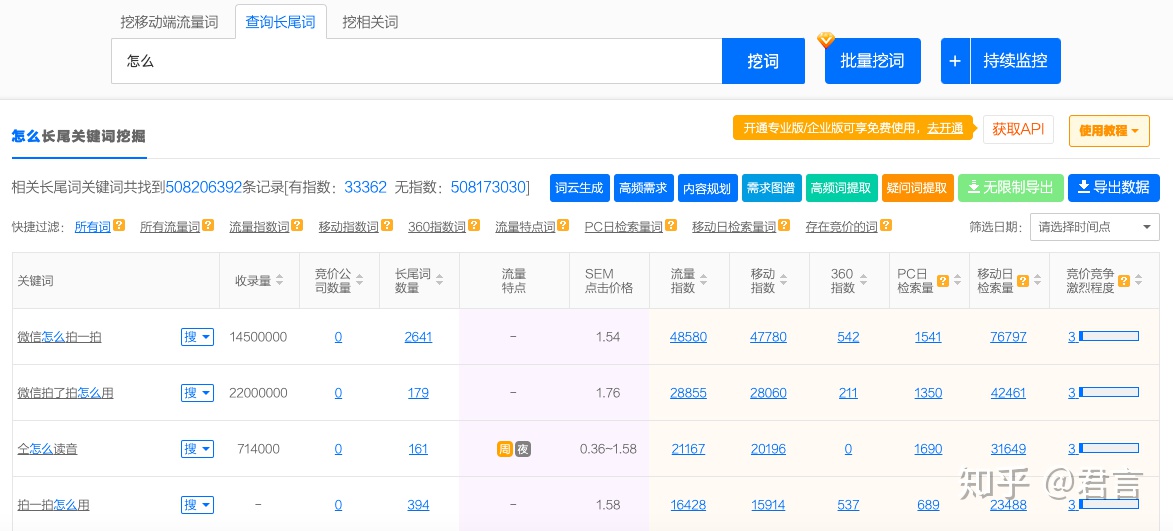
可以看到相关长尾词有5亿多,右上角”导出数据“(年VIP可以导出50W条),这样我们可以拿到跟”怎么“有关的大量长尾词,如下:
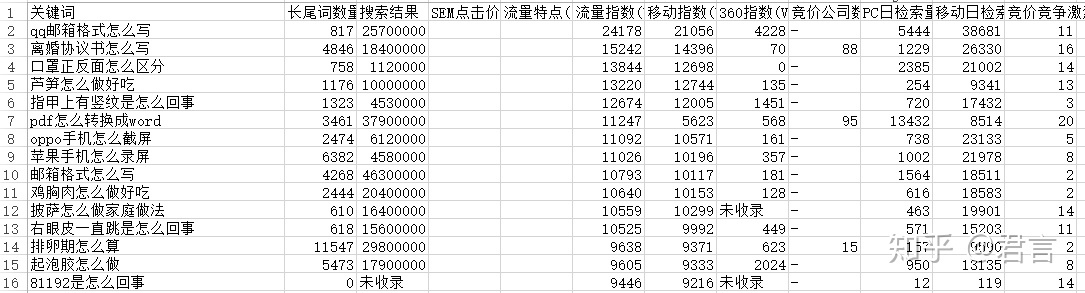
但是词数有5亿多,我们可能只能下载几十万,不一定具有代表性,全部下载及分析既不现实也无意义,所以我们只需要提取有代表性的词即可,具体方法是:
刚才导出的50W数据,用Python写个脚本,利用jieba分词模块,把一个个完整长尾词分成词根,比如:
QQ邮箱格式怎么写 –> QQ、邮箱、格式、怎么、写
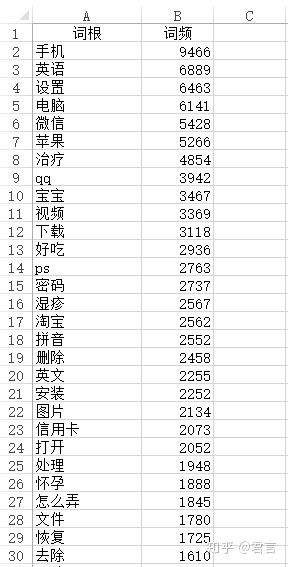
边分词的时候边自动记录每个词根的次数,即词频,结果保存到Excel里,然后在Excel里按照词频倒序排序出来,如下(分词的控制后面再说):
- 词频表示在词库里出现的次数
然后把”怎么“+上面的高频词根(如”手机“),再去5118上面拓展,导出,重复这个步骤(不包含再分词,分词只做第一次),拓展出来的词必定包含”怎么“和”手机“,如下:
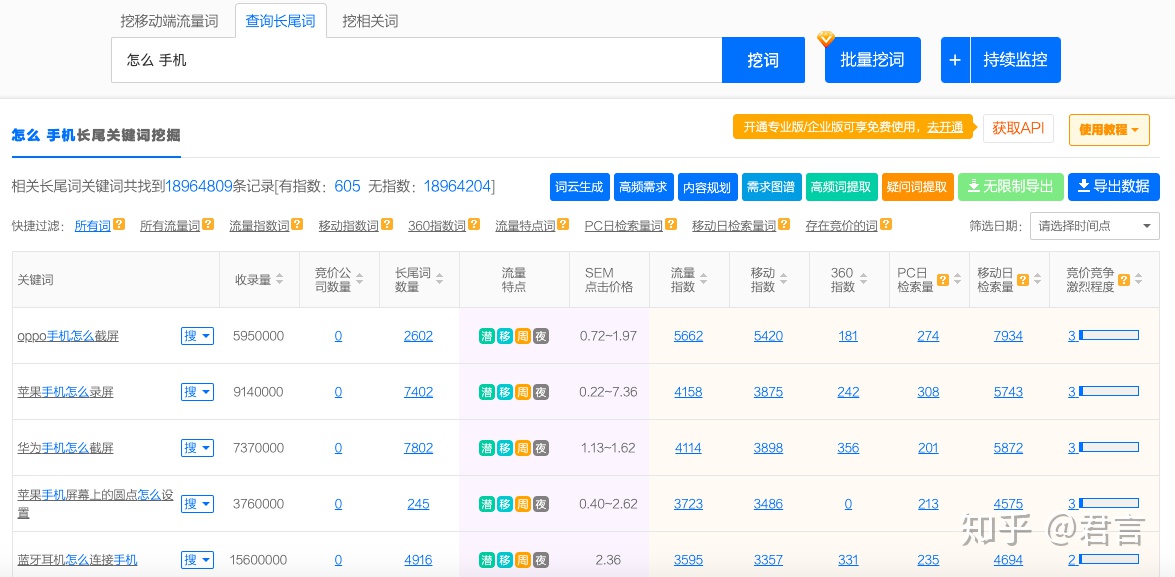
关键词往往符合2/8定律,把能覆盖80%词量的20%词根都拿去拓展,基本就能收集到有代表性的词库了(去重问题暂时不管),这里也可以结合常识:“怎么”这个词跟哪个词应该是经常出现的,结合后应该有很多长尾词的,也可以一起拿去拓展,比如:“怎么制作”
通过上面的步骤,我们已经导出了较为有代表性的长尾词库,这时你可能有百万级的关键词数据了,别急,还有其他渠道。
百度搜索:百度推广,进入百度凤巢后台,没有账户用自己手机注册一个(本条不懂也没关系,后面有更简单的)
- 推广后台

进入后台选择”关键词规划师“的工具
接下来的步骤和5118的处理方式是一样的,这两个只是渠道不同而已,5118数据量大,而百度的搜索数据无论是词还是搜索量都是官方的,很权威,我们的目的是尽可能的收集到足够多足够有代表性的词库:
- 关键词规划师
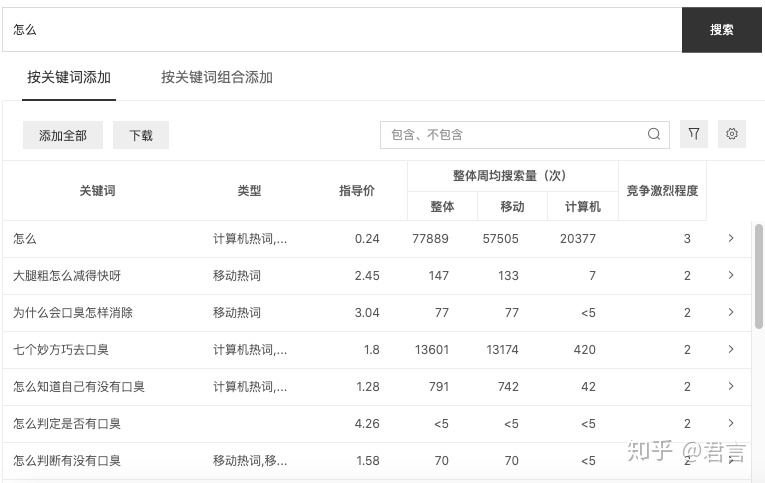
网页版使用起来比较麻烦,我们可以无视上述的方式,推荐使用这个工具:艾奇关键词工具
数据来源就是百度关键词规划师,和上面能拿到的数据是一样的。
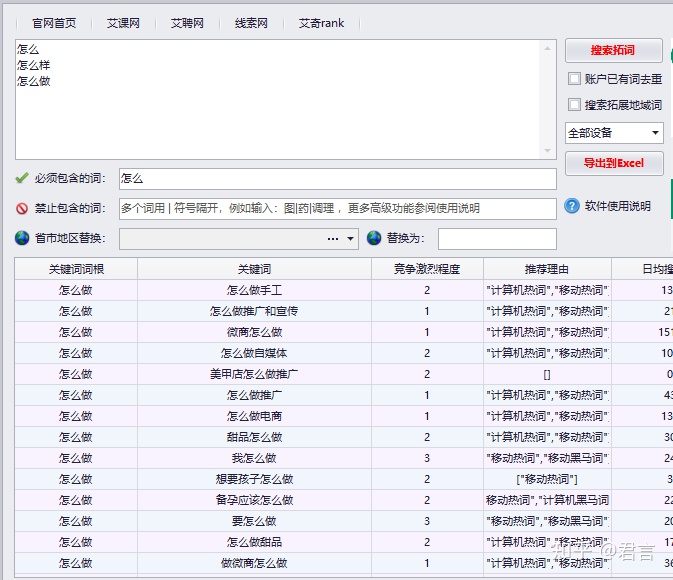
这个工具的优势在于:我们只要第一次搜索“怎么”,导出来之后还是按照之前的方法统计出词频,然后批量的把所有组合词放进去,它可以一起拓展,效率很高。
百度的数据一次不会拓展出很多,需要更多的数据,就需要不断的拓展,按我个人经验,拓展几次,有几万个词就足以,因为百度优先给你的都是搜索量相对高的,这样的词本身就具备代表性。
拓词到了这一步,其实已经累计出挺多的数据了,如果你觉得差不多了那也行,我个人认为足够分析了,如果你希望拓展更多,那也还有:
百度搜索:爱站、站长工具
到这些网站里再去运用同样的方法,导出更多的数据,方法和步骤同上处理(不同渠道导出的词,先分开处理和保存)
- 爱站
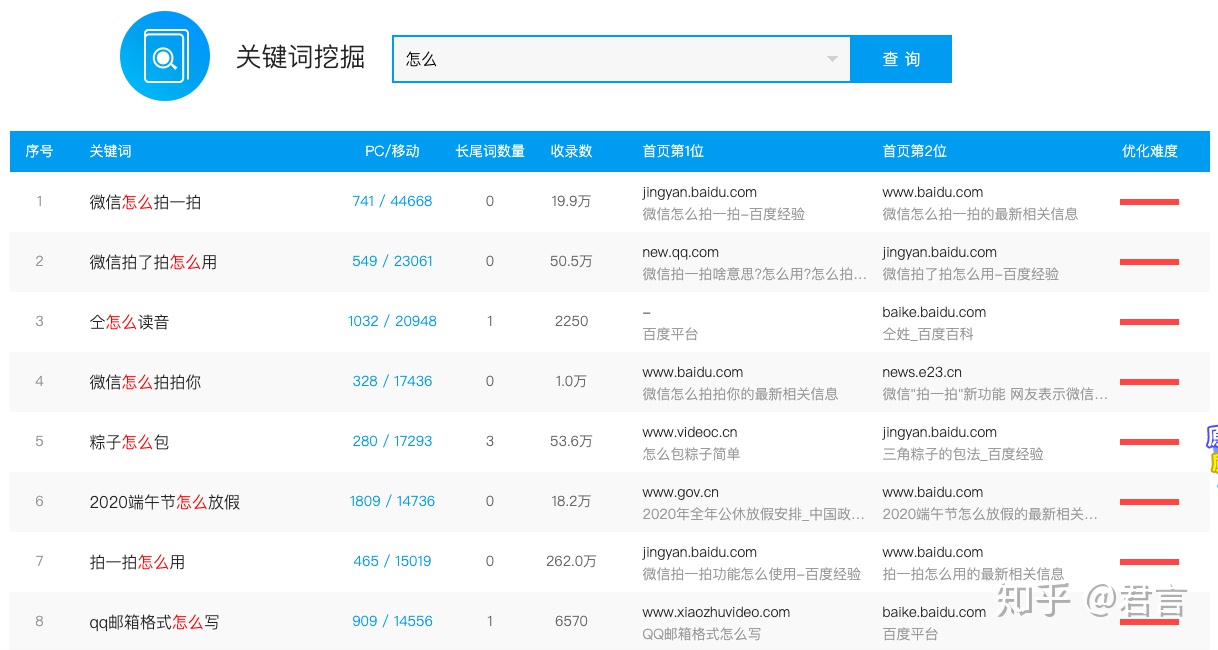
挖词的步骤到这已经可以了,不需要再去找其他挖词工具,百度和5118还有站长工具足够覆盖,当然了,搜索引擎除了百度,还有其他:搜狗、好搜、神马,他们也一样有对应的工具,一样可以按照先前的步骤去处理。
步骤2:
现在我们已经有了一批词库,可能有小几百万,分散在几个Excel里,词库里几乎覆盖了所有包含”怎么“这个词的各类长尾词(可能有些词并没有被我们收集到,但是跟它近似的同义的词我们一定有,这就够了)。
接下来简单清洗下数据,包括:
去重、去长、去短、去无效词,去非目标词(按顺序操作)
我们先把各Excel里的数据,除关键词这一列,其他列都删除,那些搜索数据、长尾数量、竞争程度,不是我们此次的分析目标,没有参考意义,我们只要“关键词”这一列。
- 只保留关键词这一列

去重:需要把一模一样的词去除
去长去短:一个正常的关键词的长度是在一定范围内的,太短没有参考意义,太长一般是有重复词根(这种一般都是用户非主观意识键入而被保存起来的),比如:
”怎么了“ 和 ”朋友圈打不开是怎么回事啊打不开朋友圈了“
去无效词:乱码、字符串、纯数字等等(一般是在5118上会出现,但还是统一处理一遍)
去非目标词:某些词根一看就不是我们想要研究的,比如一些违法乱纪的,那就把包含该词根的全部去掉,这一步骤并非必须,仅根据个人分析目的。
鉴于数据量太大,清洗数据的操作,Excel基本操作不了,而且多个分别处理也不科学,所以还是用脚本,我个人建议使用Python处理,只是简单的写些循环语句就可以了,最后把数据都保存到一份TXT文档中。
步骤3:
以上步骤都完成了后,我们得到了一份干净的关键词数据,它保存在一份TXT中:
-
这是一份50W条数据的文档
-
里面就这样
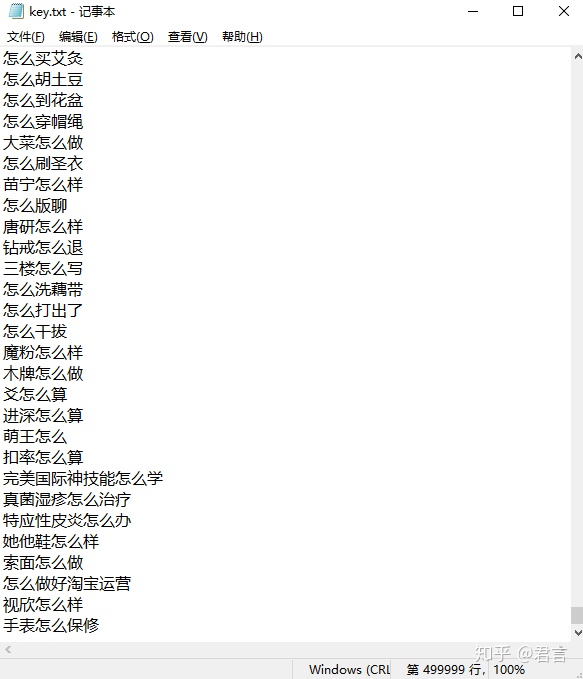
尽管已经做了清洗,但是几十万甚至几百万的关键词摆在我们眼前,依然眼花缭乱,我们根本记不住什么。
所以我使用了一个归类方式:词向量文本分类,是一种计算文本相似度的方法。
不要被这个名称吓到,他运用到的数学知识就一个,还仅限于初中水平。
因为之前从事搜索引擎营销方面的工作,对搜索引擎的工作原理有一些了解,在判断两篇文章是不是一样的时候,搜索引擎就有利用这种思路,当然那会更复杂许多,我这里的思路比较简单(下面这段纯技术细节,除非有兴趣,可以不看,不影响):
词库里的词相互之间互相比对,两两比对时,计算各自的词根向量,然后再计算两组向量的余弦值,越接近1,则表示两个词越相似,完全一样的词则会输出1,当两个词相似度大于一定值(可不断计算再根据结果调整,自己根据经验设定,比如0.8),则将它们归为一类,比如:
”QQ邮箱格式怎么写“ 和 ”QQ邮箱格式如何写“
所有词根包含:QQ、邮箱、格式、怎么、如何、写
把每个词根分别到两个长尾词里挨个计算词频,即可转换为两组向量:
(1,1,1,1,0,1)、(1,1,1,0,1,1)
两者计算余弦值等于:0.8
这是技术思路,实现起来还有挺多麻烦的事情,这里不展开,有兴趣可以讨论。
50W的数据,从最开始要跑几天(两两相比,属于空间复杂度的问题,数据量越多,计算时间指数增长)被我慢慢优化到几个小时左右,有空还会再优化一下程序计算方式,能达到目的即可,我们并不是做工程师。
自动归类完后的数据如下显示:
- 部分需求类别

这样一份Excel,已经自动帮我们归类好相似的关键词,不同类的词会间隔开,好处在于:
1:某些词可能只是小部分字眼不同,但实际表述的都是一件事,程序能帮你归类出来
2:聚集在一起的一批词,我们一眼就可以看出这是一个什么样的需求,越多越清晰
3:相关的已经归类在一起了,后面不会再出现类似需求,不会反复干扰
如果你是SEMER,应该可以发现,这个方式可以为一个账户快速的把单元自动区分好,比如第一个类别可以建一个”烫伤怎么办“的单元,一个好的账户结构,单元很重要,关系到后续词库的更新
一份百万级的词库文档,被我们归类成了若干份独立的需求集合,剩下的就是花时间去看,看到有意思的、合适的、不可思议的需求,都可以去了解,慢慢品,一定有很多你想象不到但就是真实存在的需求。
当然了,不是什么需求都一定有商业价值,也不是什么需求都可以做。
当我们在文档里看到一个想了解的需求,应该怎么做呢?
步骤4:
比如我发现一个挺有意思的东西:

你可能经常看到"PDF转Word"的需求,但是转成一张图,应该很少见,如果平时看到了也不会在意,但是当一片词出现在你眼前时,你就会觉得奇怪,现在我们拿到百度搜索看看:
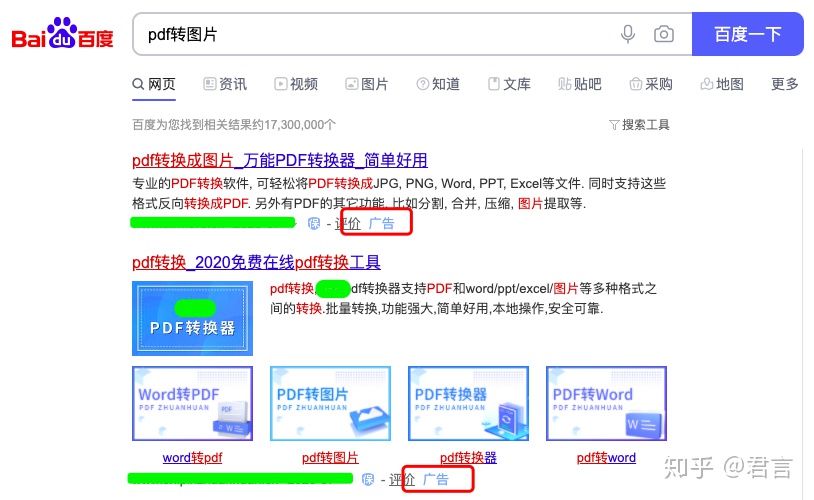
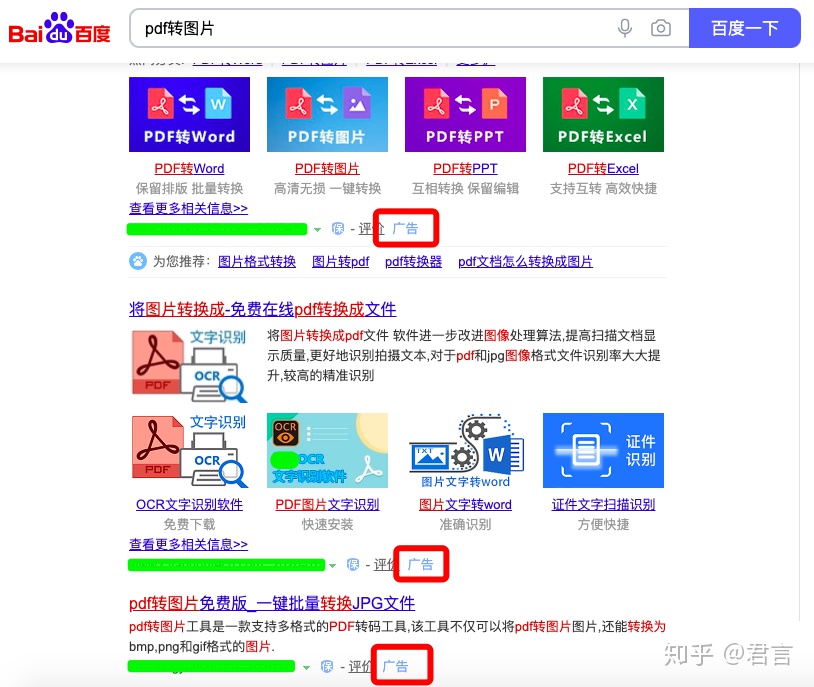
不搜你都不知道,首屏5个广告位全满,原来这么不起眼的东西也能赚钱,一个PDF转图片的小功能,大不了自己截图一下的事情,居然也可以拿来做成一个服务卖给别人,而且竞争还很激烈。
能赚多少?好赚吗?不知道!
这时我们可以:
打开他们的广告页面了解,
可以找他们的客服聊,
加他们的微信,
看他们的朋友圈,
当你确定想做某个项目,最好花钱购买一次,体验一遍所有环节。
持续跟踪他们一段时间,如果每天还在投钱,大概率是能赚的,接下去,你就依样画葫芦吧,当然了,如果能找到他们当中的不足之处加以优化,那更好。
除了百度,任何你能找到的搜索引擎,比如:淘宝、微博、抖音、头条、微信,都可以拿去搜一搜,你会发现商机越来越明确、思路越来越明朗。
-
微信上有人做了专门的小程序和公众号
-
万能的某宝也少不了,销量还很可观

关键词就是有这样的特性,我们靠想,是绝对不可能凭空想出来的,即使人家就是用这个在赚着钱,但是我们就是不知道,而把数据都收集过来,再分类,那就可以清晰的一个个去了解了。
几个小细节提一下:
1:无论是拓词还是归类,这两个环节都很依赖“分词”这个功能,分词包含两个重要问题:词频文档建立、忽略无效词根。
这两点做得好,词频更有效、归类更准确
2:上述以“怎么”这个词做演示,其实类似的:什么、如何、怎样、能不能、是不是、可不可以、需不需要,等等等等都是一样的,有精力可以把这些都做一遍,在程序归类的过程中,把这些词都忽略掉,在计算相似度时,不考虑他们,比如:
“QQ邮箱格式怎么写” 和 “QQ邮箱格式如何写”
其实我们可以认为是完全一样的一个词,那这样能归类的需求就更多了。
3:我们之前挖掘到项目之后,做了一段时间的考察,然后选择在广告平台做付费投放,但并不是什么项目都一定要做成生意,当你发现很多人会问一些问题,那么是不是可以考虑把这些做成自媒体(文章、短视频),持续的输出相关领域的内容,又或者你可以专门开发出一门网课,毕竟现在是知识付费时代、内容创作时代。
小结:
以上是通过广泛的方向去挖掘隐藏商机的步骤,之所以是广泛,是因为我们使用了“怎么”,”什么“等宽泛的词根,它包罗万象,但是比较泛,如果你已经限定了某一领域,那在接下来的另一篇文章,我会讲解使用垂直行业的词根来挖掘,同时使用另一种归类方式,让数据自动以思维导图的形式更直观的显示在你面前。
关于程序方面的相关处理,我再考虑有空整理一份出来,力求可以让非业内人士也能直接上手操作,我希望大家明白的是,技术只是解决问题的手段,思路才是关键,所以技术本身并不值钱也不可怕,不要把心思花在这方面。
Reference
1、 https://zhuanlan.zhihu.com/p/157846204
打赏
微信

|
支付宝

|
|---|---|
| 万分感谢 |
- 原文作者:冷眼
- 原文链接:https://cold-eye.github.io/post/data-mining-1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。