Streamlit开发手册 http://cw.hubwiz.com/card/c/streamlit-manual/
本文代码
1、情感分类
情感分类是自然语言处理(NLP)中的一个经典问题,目的是判断一个语句的情感倾向是积极(Positive)还是消极(Negative)。
例如,“I love Python!”这句话应当被归类为Positive,而“Python is the worst!”则应当被归类为Negative。
2、Flair开发库
很多流行的机器学习开发库都提供了情感分类器的实现,从简单和效果方面考虑,在这个教程里我们使用Flair,一个顶级的NLP分类器开发包。
可以执行如下命令安装Flair:
3、Sentiment140数据集
任何数据科学项目都需要数据集,Sentiment140数据集是我们这个项目的绝配。该数据集包含了160万条标注好的tweet微博,标注0表示消极,4表示积极。
可以从这里下载Sentiment140数据集。
4、数据载入及预处理
一旦下载好Sentiment140数据集,就可以使用如下代码载入数据:
1
2
3
4
5
6
7
8
|
import pandas as pd
col_names = ['sentiment','id','date','query_string','user','text']
data_path = 'training.1600000.processed.noemoticon.csv'
tweet_data = pd.read_csv(data_path, header=None, names=col_names, encoding="ISO-8859-1").sample(frac=1) # .sample(frac=1) shuffles the data
tweet_data = tweet_data[['sentiment', 'text']] # Disregard other columns
print(tweet_data.head())
|
运行上面的代码将输出如下结果:
sentiment text
1459123 4 @minalpatel Any more types of glassware you'd...
544833 0 I was a bit puzzled as to why it seemed to it...
398665 0 Yay...my car is ready....Was about 2500 miles...
708548 0 @JoshEJosh How ya been? I MISS you!
264000 0 @MrFresh0587 yeah i know. well...i'm going to...
不过,因为我们使用 .sample(frac=1)随机打乱了数据的先后次序,你得到的结果可能略有不同。
现在数据还很乱,我们先进行预处理:
1
2
3
4
5
6
7
8
|
import re
allowed_chars = ' AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789~`!@#$%^&*()-=_+[]{}|;:",./<>?'
punct = '!?,.@#'
maxlen = 280
def preprocess(text):
return ''.join([' ' + char + ' ' if char in punct else char for char in [char for char in re.sub(r'http\S+', 'http', text, flags=re.MULTILINE) if char in allowed_chars]])[:maxlen]
|
上面的函数略为有点乏味,但是简而言之,这段代码的目的是剔除文本中所有不能识别的字符、链接等并截断为280个字符。有更好的办法来进行链接清理等预处理,不过我们这里就用最朴素的方法了。
Flair对数据格式有特定的要求,看起来是这样:
__label__<LABEL> <TEXT>
在我们的微博情感分析应用中,数据整理后应该是这样:
__label__4 <PRE-PROCESSED TWEET>
__label__0 <PRE-PROCESSED TWEET>
...
为此,我们需要三个步骤:
1、执行预处理函数
1
|
tweet_data['text'] = tweet_data['text'].apply(preprocess)
|
2、在每个情感标记前添加__label__前缀
1
|
tweet_data['sentiment'] = '__label__' + tweet_data['sentiment'].astype(str)
|
3、保存数据
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import os
# Create directory for saving data if it does not already exist
data_dir = './processed-data'
if not os.path.isdir(data_dir):
os.mkdir(data_dir)
# Save a percentage of the data (you could also only load a fraction of the data instead)
amount = 0.125
tweet_data.iloc[0:int(len(tweet_data)*0.8*amount)].to_csv(data_dir + '/train.csv', sep='\t', index=False, header=False)
tweet_data.iloc[int(len(tweet_data)*0.8*amount):int(len(tweet_data)*0.9*amount)].to_csv(data_dir + '/test.csv', sep='\t', index=False, header=False)
tweet_data.iloc[int(len(tweet_data)*0.9*amount):int(len(tweet_data)*1.0*amount)].to_csv(data_dir + '/dev.csv', sep='\t', index=False, header=False)
|
在上面的代码中,你可能注意到了两个问题:
- 我们仅保存了部分数据。这是因为Sentiment140数据集太大了,如果Flair加载 完整的数据集需要太多的内存。
- 我们将数据分割为训练集、测试集和开发集。当Flair载入数据时,它需要数据 按这种方法拆分。默认情况下,拆分比例为8-1-1,即80%的数据进训练集、10% 的数据进测试集、10%的数据进开发集
现在,数据准备好了!
5、基于Flair的文本情感分类实现
在这个教程中,我们仅涉及Flair的基础。如果你需要更多细节,推荐你查看Flair的官方文档。
首先我们用Flair的NLPTaskDataFetcher 类载入数据:
1
2
3
4
|
from flair.data_fetcher import NLPTaskDataFetcher
from pathlib import Path
corpus = NLPTaskDataFetcher.load_classification_corpus(Path(data_dir), test_file='test.csv', dev_file='dev.csv', train_file='train.csv')
|
然后我们构造一个标签字典来记录语料库中分配给文本的所有标签:
1
|
label_dict = corpus.make_label_dictionary()
|
现在可以载入Flair内置的GloVe词嵌入了:
1
2
3
4
5
6
|
from flair.embeddings import WordEmbeddings, FlairEmbeddings
word_embeddings = [WordEmbeddings('glove'),
# FlairEmbeddings('news-forward'),
# FlairEmbeddings('news-backward')
]
|
注释掉的两行代码是Flair提供的选项,用于得到更好的效果,不过我的内存有限,因此无法进行测试。
载入词嵌入向量后,用下面的代码进行初始化:
1
2
3
|
from flair.embeddings import DocumentRNNEmbeddings
document_embeddings = DocumentRNNEmbeddings(word_embeddings, hidden_size=512, reproject_words=True, reproject_words_dimension=256)
|
现在整合词嵌入向量和标签字典,得到一个TextClassifier模型:
1
2
3
|
from flair.models import TextClassifier
classifier = TextClassifier(document_embeddings, label_dictionary=label_dict)
|
接下来我们可以创建一个ModelTrainer实例来用我们的语料库训练模型:
1
2
3
|
from flair.trainers import ModelTrainer
trainer = ModelTrainer(classifier, corpus)
|
一旦开始训练,我们需要等一会儿了:
1
2
3
4
5
6
|
trainer.train('model-saves',
learning_rate=0.1,
mini_batch_size=32,
anneal_factor=0.5,
patience=8,
max_epochs=200)
|
在模型训练完之后,可以使用如下的代码进行测试:
1
2
3
4
5
6
7
8
9
10
11
|
from flair.data import Sentence
classifier = TextClassifier.load('model-saves/final-model.pt')
pos_sentence = Sentence(preprocess('I love Python!'))
neg_sentence = Sentence(preprocess('Python is the worst!'))
classifier.predict(pos_sentence)
classifier.predict(neg_sentence)
print(pos_sentence.labels, neg_sentence.labels)
|
你应该可以得到类似下面这样的结果:
1
|
[4 (0.9758405089378357)] [0 (0.8753706812858582)]
|
看起来预测是正确的!
不错,现在我们有了一个可以预测单条tweet的感情色彩是积极或消极。不过这还不是太有用,那么应该怎么改进?
我的想法是抓取指定查询条件的最新tweet微博,逐个进行情感分类,然后计算积极/消极的比率。
我个人喜欢用twitterscraper来抓twitter微博,虽然它不算快,但你可以绕过twitter设置的请求限制。用下面的命令安装twitterscraper:
1
|
pip3 install twitterscraper
|
安装好了。稍后我们再进行具体的抓取。
7、编写Streamlit脚本
创建一个新的文件main.py,然后先引入一些模块:
1
2
3
4
5
6
7
8
|
import datetime as dt
import re
import pandas as pd
import streamlit as st
from flair.data import Sentence
from flair.models import TextClassifier
from twitterscraper import query_tweets
|
接下来,我们可以进行一些基本的处理,例如设置页面标题、载入分类模型:
1
2
3
4
5
6
|
# Set page title
st.title('Twitter Sentiment Analysis')
# Load classification model
with st.spinner('Loading classification model...'):
classifier = TextClassifier.load('models/best-model.pt')
|
with st.spinner 这部分代码块让我们可以在加载分类模型时给用户一个进度提示。
接下来我们可以复制之前写的预处理函数:
1
2
3
4
5
6
7
8
|
import re
allowed_chars = ' AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789~`!@#$%^&*()-=_+[]{}|;:",./<>?'
punct = '!?,.@#'
maxlen = 280
def preprocess(text):
return ''.join([' ' + char + ' ' if char in punct else char for char in [char for char in re.sub(r'http\S+', 'http', text, flags=re.MULTILINE) if char in allowed_chars]])[:maxlen]
|
我们首先实现单个tweet微博的分类:
1
2
3
|
st.subheader('Single tweet classification')
tweet_input = st.text_input('Tweet:')
|
只要输入文本不是空的,我们就进行如下处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
if tweet_input != '':
# Pre-process tweet
sentence = Sentence(preprocess(tweet_input))
# Make predictions
with st.spinner('Predicting...'):
classifier.predict(sentence)
# Show predictions
label_dict = {'0': 'Negative', '4': 'Positive'}
if len(sentence.labels) > 0:
st.write('Prediction:')
st.write(label_dict[sentence.labels[0].value] + ' with ',
sentence.labels[0].score*100, '% confidence')
|
使用st.write可以写入任何文本,甚至可以直接显式Pandas数据帧。
好了,现在可以运行:
结果看起来是这样:
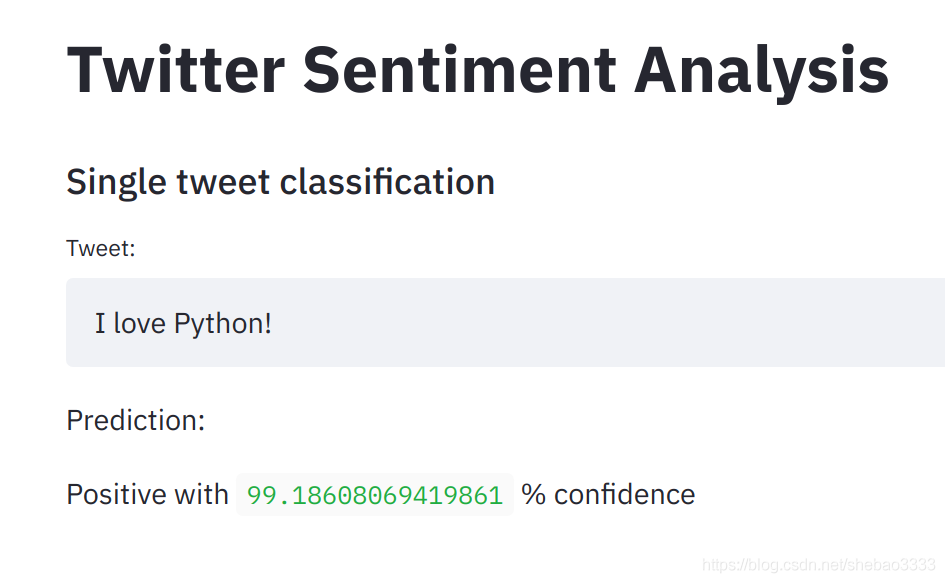
接下来我们可以实现之前的想法了:搜索某个主题的twitter微博并计算情感正负比。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
st.subheader('Search Twitter for Query')
# Get user input
query = st.text_input('Query:', '#')
# As long as the query is valid (not empty or equal to '#')...
if query != '' and query != '#':
with st.spinner(f'Searching for and analyzing {query}...'):
# Get English tweets from the past 4 weeks
tweets = query_tweets(query, begindate=dt.date.today() - dt.timedelta(weeks=4), lang='en')
# Initialize empty dataframe
tweet_data = pd.DataFrame({
'tweet': [],
'predicted-sentiment': []
})
# Keep track of positive vs. negative tweets
pos_vs_neg = {'0': 0, '4': 0}
# Add data for each tweet
for tweet in tweets:
# Skip iteration if tweet is empty
if tweet.text in ('', ' '):
continue
# Make predictions
sentence = Sentence(preprocess(tweet.text))
classifier.predict(sentence)
sentiment = sentence.labels[0]
# Keep track of positive vs. negative tweets
pos_vs_neg[sentiment.value] += 1
# Append new data
tweet_data = tweet_data.append({'tweet': tweet.text, 'predicted-sentiment': sentiment}, ignore_index=True)
|
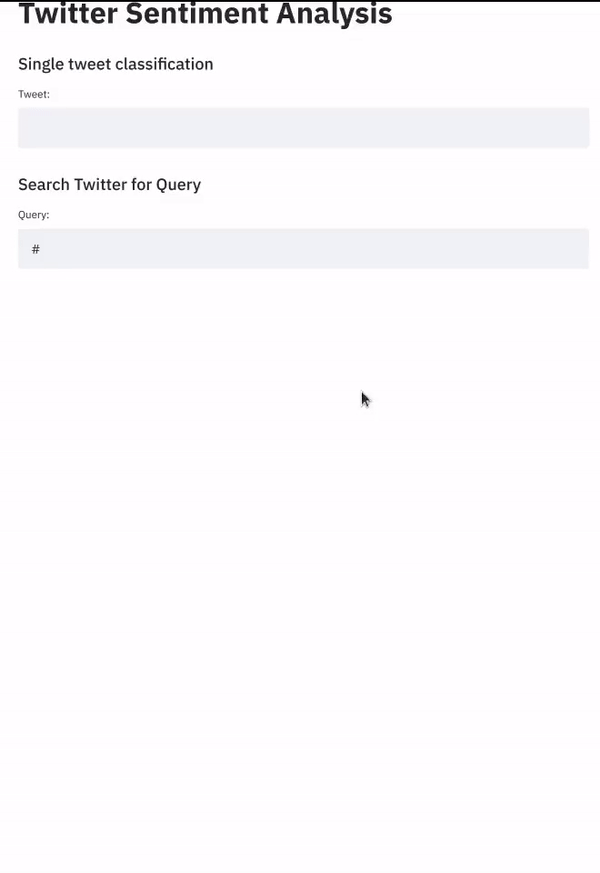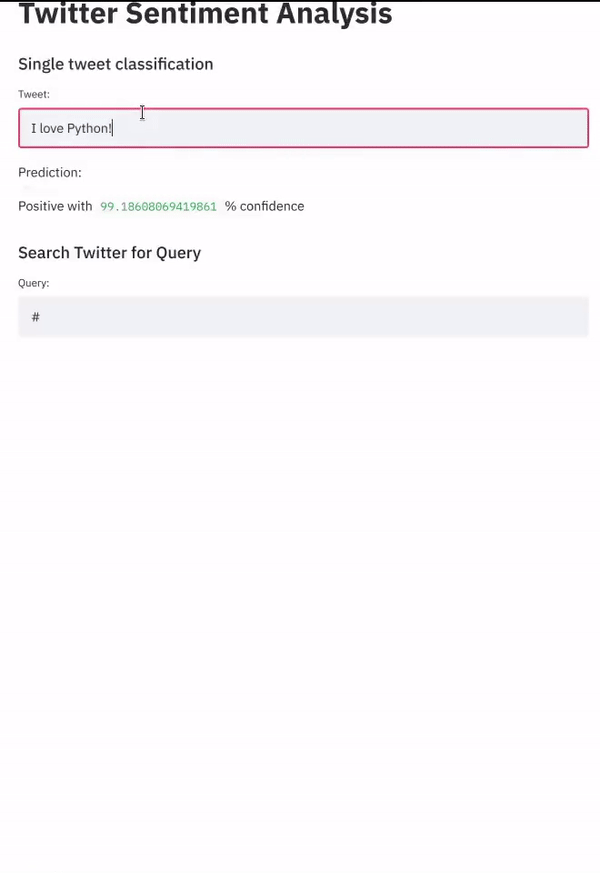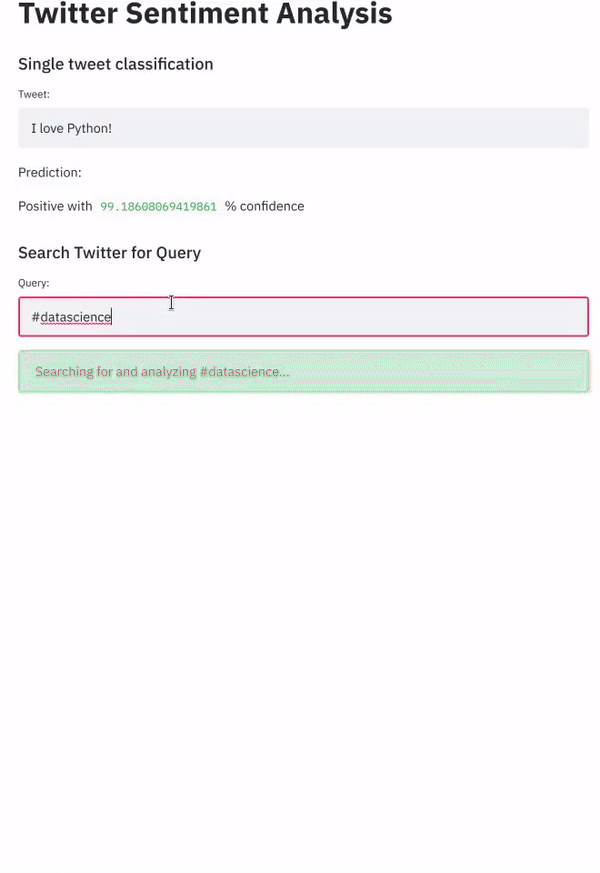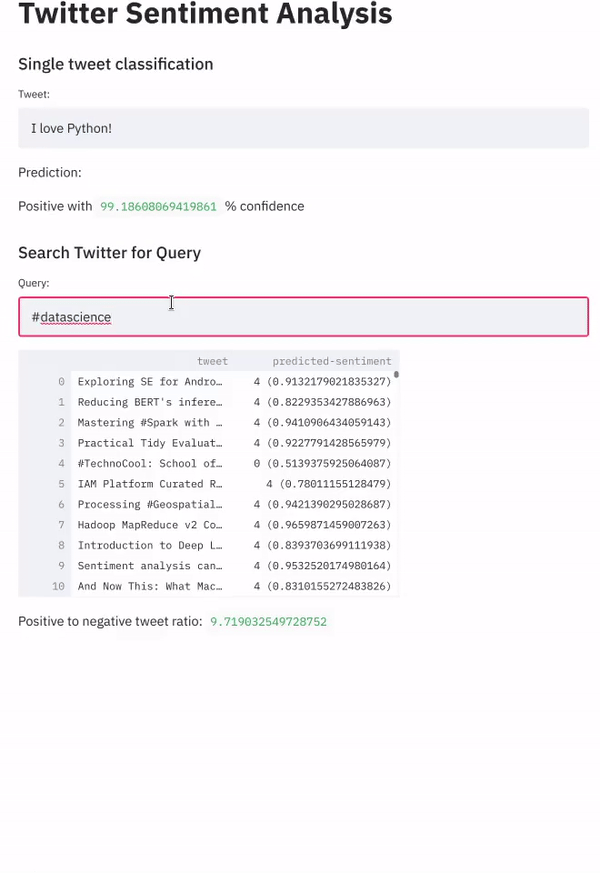
最后,我们显示采集的数据:
1
2
3
4
5
6
7
8
9
|
try:
st.write(tweet_data)
# Show positive to negative tweet ratio
try:
st.write('Positive to negative tweet ratio:', pos_vs_neg['4']/pos_vs_neg['0'])
except ZeroDivisionError: # if no negative tweets
st.write('All postive tweets')
except NameError: # if no queries have been made yet
pass
|
再次运行应用,结果如下:

下面我们完整的streamlit应用脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
import datetime as dt
import re
import pandas as pd
import streamlit as st
from flair.data import Sentence
from flair.models import TextClassifier
from twitterscraper import query_tweets
# Set page title
st.title('Twitter Sentiment Analysis')
# Load classification model
with st.spinner('Loading classification model...'):
classifier = TextClassifier.load('models/best-model.pt')
# Preprocess function
allowed_chars = ' AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789~`!@#$%^&*()-=_+[]{}|;:",./<>?'
punct = '!?,.@#'
maxlen = 280
def preprocess(text):
# Delete URLs, cut to maxlen, space out punction with spaces, and remove unallowed chars
return ''.join([' ' + char + ' ' if char in punct else char for char in [char for char in re.sub(r'http\S+', 'http', text, flags=re.MULTILINE) if char in allowed_chars]])
### SINGLE TWEET CLASSIFICATION ###
st.subheader('Single tweet classification')
# Get sentence input, preprocess it, and convert to flair.data.Sentence format
tweet_input = st.text_input('Tweet:')
if tweet_input != '':
# Pre-process tweet
sentence = Sentence(preprocess(tweet_input))
# Make predictions
with st.spinner('Predicting...'):
classifier.predict(sentence)
# Show predictions
label_dict = {'0': 'Negative', '4': 'Positive'}
if len(sentence.labels) > 0:
st.write('Prediction:')
st.write(label_dict[sentence.labels[0].value] + ' with ',
sentence.labels[0].score*100, '% confidence')
### TWEET SEARCH AND CLASSIFY ###
st.subheader('Search Twitter for Query')
# Get user input
query = st.text_input('Query:', '#')
# As long as the query is valid (not empty or equal to '#')...
if query != '' and query != '#':
with st.spinner(f'Searching for and analyzing {query}...'):
# Get English tweets from the past 4 weeks
tweets = query_tweets(query, begindate=dt.date.today() - dt.timedelta(weeks=4), lang='en')
# Initialize empty dataframe
tweet_data = pd.DataFrame({
'tweet': [],
'predicted-sentiment': []
})
# Keep track of positive vs. negative tweets
pos_vs_neg = {'0': 0, '4': 0}
# Add data for each tweet
for tweet in tweets:
# Skip iteration if tweet is empty
if tweet.text in ('', ' '):
continue
# Make predictions
sentence = Sentence(preprocess(tweet.text))
classifier.predict(sentence)
sentiment = sentence.labels[0]
# Keep track of positive vs. negative tweets
pos_vs_neg[sentiment.value] += 1
# Append new data
tweet_data = tweet_data.append({'tweet': tweet.text, 'predicted-sentiment': sentiment}, ignore_index=True)
# Show query data and sentiment if available
try:
st.write(tweet_data)
try:
st.write('Positive to negative tweet ratio:', pos_vs_neg['4']/pos_vs_neg['0'])
except ZeroDivisionError: # if no negative tweets
st.write('All postive tweets')
except NameError: # if no queries have been made yet
pass
|
Reference
1、 https://yq.aliyun.com/articles/743284
2、 Streamlit开发手册 http://cw.hubwiz.com/card/c/streamlit-manual/
3、 https://medium.com/analytics-vidhya/building-a-twitter-sentiment-analysis-app-using-streamlit-d16e9f5591f8
4、 https://discuss.streamlit.io/t/remove-made-with-streamlit-from-bottom-of-app/1370
5、 https://www.streamlit.io/
打赏
微信

|
支付宝

|
| 万分感谢 |
|